在理解 DQN 魔法陣的結構後,本篇來帶大家訓練 DQN 模型玩 Flappy Bird,引用參考的程式碼在此:https://github.com/yanpanlau/Keras-FlappyBird
教電腦玩 Flappy Bird
Keras 2.1.5
Python 3.6.7
TensorFlow 1.11.0
Note: GPU 的環境版本請參考 github
透過套件pygame,訪問FlappyBird API
import wrapped_flappy_bird as game
x_t1_colored, r_t, terminal = game_state.frame_step(a_t)
frame_step函數中的a_t只有參數0和1:
API 返回 xt1colored、rt 和 terminal,其中 rt 有三種表示:
terminal 為boolean值,表示遊戲是否結束。
為了加快訓練速度,對圖片作下列前處理:
x_t1 = skimage.color.rgb2gray(x_t1_colored)
x_t1 = skimage.transform.resize(x_t1,(80,80))
x_t1 = skimage.exposure.rescale_intensity(x_t1, out_range=(0, 255))
x_t1 = x_t1.reshape(1, 1, x_t1.shape[0], x_t1.shape[1])
s_t1 = np.append(x_t1, s_t[:, :3, :, :], axis=1)
將處理完的圖片餵入 CNN
Relu
adam
def buildmodel():
print("Now we build the model")
model = Sequential()
model.add(Convolution2D(32, 8, 8, subsample=(4,4),init=lambda shape, name: normal(shape, scale=0.01, name=name), border_mode='same',input_shape=(img_channels,img_rows,img_cols)))
model.add(Activation('relu'))
model.add(Convolution2D(64, 4, 4, subsample=(2,2),init=lambda shape, name: normal(shape, scale=0.01, name=name), border_mode='same'))
model.add(Activation('relu'))
model.add(Convolution2D(64, 3, 3, subsample=(1,1),init=lambda shape, name: normal(shape, scale=0.01, name=name), border_mode='same'))
model.add(Activation('relu'))
model.add(Flatten())
model.add(Dense(512, init=lambda shape, name: normal(shape, scale=0.01, name=name)))
model.add(Activation('relu'))
model.add(Dense(2,init=lambda shape, name: normal(shape, scale=0.01, name=name)))
adam = Adam(lr=1e-6)
model.compile(loss='mse',optimizer=adam)
print("We finish building the model")
return model
action
reward
D,這樣一來,在訓練網絡時,使用 memory D 的隨機 mini-batches,而非最鄰近的 episode,來提高神經網絡的穩定性。if t > OBSERVE:
#sample a minibatch to train on
minibatch = random.sample(D, BATCH)
inputs = np.zeros((BATCH, s_t.shape[1], s_t.shape[2], s_t.shape[3])) #32, 80, 80, 4
targets = np.zeros((inputs.shape[0], ACTIONS)) #32, 2
#Now we do the experience replay
for i in range(0, len(minibatch)):
state_t = minibatch[i][0]
action_t = minibatch[i][1] #This is action index
reward_t = minibatch[i][2]
state_t1 = minibatch[i][3]
terminal = minibatch[i][4]
# if terminated, only equals reward
inputs[i:i + 1] = state_t #I saved down s_t
targets[i] = model.predict(state_t) # Hitting each buttom probability
Q_sa = model.predict(state_t1)
if terminal:
targets[i, action_t] = reward_t
else:
targets[i, action_t] = reward_t + GAMMA * np.max(Q_sa)
loss += model.train_on_batch(inputs, targets)
s_t = s_t1
t = t + 1
我們文章中尚未提到深度強化學習的一些問題,例如對環境的 Overfitting、不穩定性,或是一個好的 reward 函數往往不好設計等等,但不打算在這裡探討這些問題。
[魔法陣系列] Deep Q Network(DQN)之術式解析 和本篇文章僅是帶大家到深度強化學習的新手村,事實上有很多研究者投入研究和未來潛在性可參考下圖,如果對這塊有興趣的見習魔法使們,就繼續挖掘下去吧!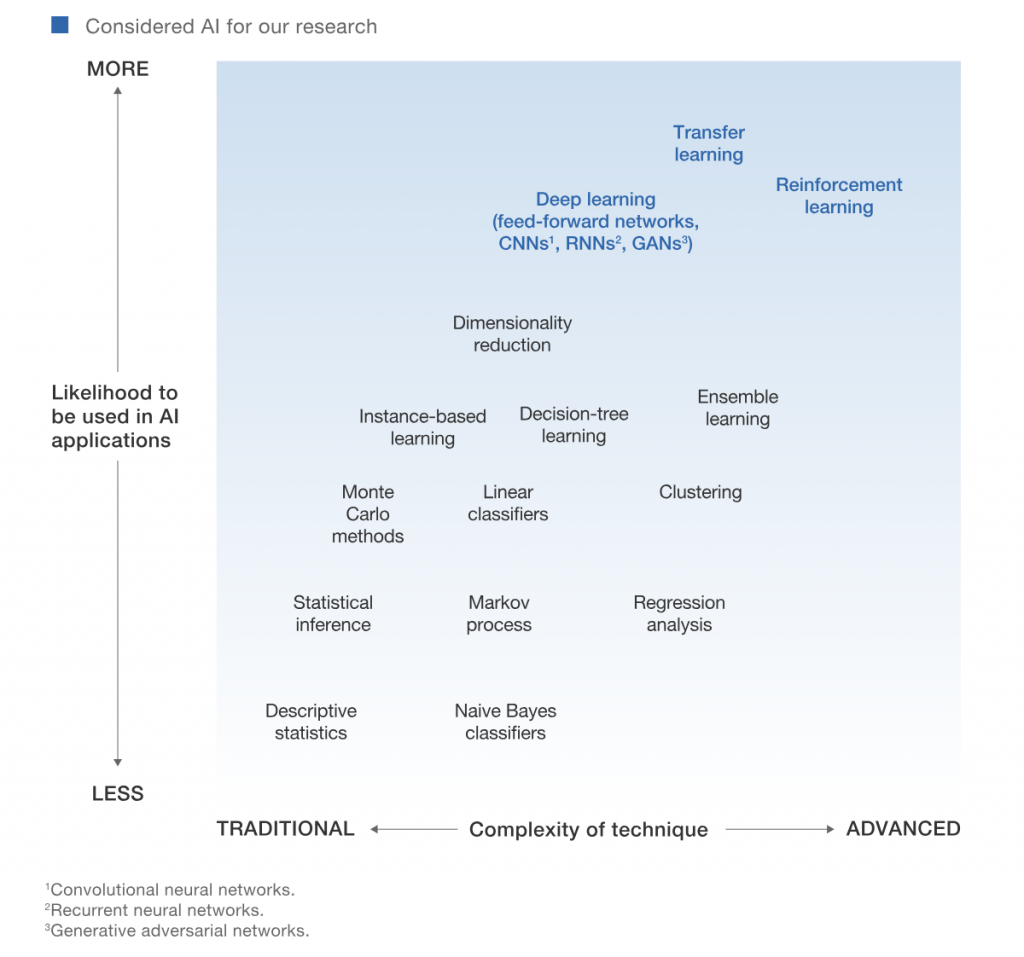
圖片來源:https://www.mckinsey.com/featured-insights/artificial-intelligence/notes-from-the-ai-frontier-applications-and-value-of-deep-learning

